





Seguindo a série de trabalhos da faculdade :D, agora brincando um pouco com Machine Learning.
Classificação de textos consiste em associar cada texto a uma determinada classe baseada em seu conteúdo, por exemplo, podemos associar um comentário sobre um produto ou serviço a uma classe “Negativo” quando for um comentário negativo sobre o produto ou a uma classe “Positivo” quando for um comentário positivo sobre o mesmo.
Isso acontece também nos servidores de e-mails para poder classificar um e-mail como spam, por exemplo, e assim direcioná-lo para o diretório spam.

Fazer isso a uma quantidade grande de comentários pode ser útil para se ter uma visão de como as pessoas, possivelmente os clientes ou usuários, estão se sentindo em relação a um produto, por exemplo, mas pode ser trabalhoso e talvez inviável fazer isso manualmente, ai entra o Machine Learning para automatizar esse processo.
Para utilizar Machine Learning na classificação de textos, uma das técnicas mais utilizadas é usar aprendizado supervisionado, onde temos uma coleção de dados já processados e classificados nas suas determinadas classes, então entramos esses dados como input para o algoritmo que irá ‘aprender’ as características que representam cada classe com utilizando esses dados já classificados.
Os problemas mais frequentes que fazem uso de aprendizado supervisionado são problemas de ‘regressão’ onde temos que mapear as variáveis em um resultado continuo, tentando predizer um resultado, e problemas de ‘classificação’, que será o caso de estudo, que se pretende definir classes distintas às variáveis de entrada que no caso serão comentários sobre filmes.
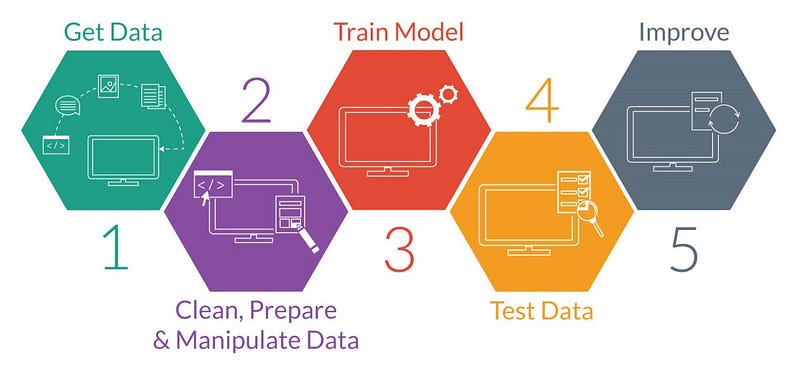
Para implementar um modelo de Machine Learning normalmente segue-se um fluxo, que pode variar dependendo do objetivo final, em cima dos dados antes que o modelo entre em produção, que podemos definir basicamente em:
- Obtenção dos dados;
- Pré-processamento;
- Treinamento;
- Teste;
- Aperfeiçoamento;
Obtenção dos dados

Nesta etapa obtemos os dados “crus” seja de qualquer fonte, banco de dados, arquivos, paginas web, etc. É importante saber que os dados devem ser relevantes para o domínio do problema, selecionando dados diferentes do que se deseja analisar pode prejudicar o resultado final e trazer resultados incoerentes com a realidade.
Para este caso eu realizei scraping (web scraping é uma técnica para
captura automatizada de dados de páginas web, sejam textos, imagens, documentos, etc.)
de um site sobre cinema e peguei os comentários das pessoas que fizeram
avaliações de diversos filmes. Como no site tinha a avaliação dos
determinados filmes em forma de estrelas, assumi isso para determinar se
um comentário é positivo ou negativo, para ficar mais
discretizado descartei os comentários com 3 estrelas por assumir que
seriam “neutros”, e defini os comentários com 4 e 5 estrelas como
positivos e os que tiveram 2 ou 1 estrelas como negativo, então salvei
em dois arquivos separados CommentsPositive e CommentsNegative.
Pré-processamento

Nesta etapa realizamos a preparação dos dados, padronizando, retirando inconsistências, etc, para após servir como entrada para o treinamento do algoritmo. Esse processo pode ser composta de diversas sub etapas que podem variar dependendo do objetivo final e necessidade. Para esse caso de estudo fiz as seguintes sub-etapas para preparar os dados:
Padronizar tudo em letra minúsculas
Como processo de padronização dos comentários transformei tudo em letras minúsculas;
Remoção de acentos
Também removi toda a acentuação dos comentários;
Remoção de pontuação
As pontuações não têm significado para este caso então foi removido todo tipo de pontuações;
Remoção de espaços em branco
Foi removido todo espaço em branco desnecessário;
Remoção de caracteres repetidos
Também foi removidos caracteres repetidos, por exemplo, o seguinte comentário: “filme muuuuuuiiitttooooo boooooooommmmm”, foi transformado em: “filme muito bom”;
Remoção de stopwords
Esta é uma técnica muito utilizada no pré-processamento de textos para classificação com Machine Learning, consiste na remoção de palavras muito frequentes e que não são tenham nenhum valor semântico no texto, como exemplo os artigos e preposições, isso também diminui a quantidade de palavras a serem processadas melhorando o tempo da tarefa de treinamento e teste;
Stemming
Stemming também é um método bastante utilizado em textos antes de serem processado por algum algoritmo de Machine Learning.
Os textos comumente possuem diversas palavras derivadas ou flexionadas, o processo de stemming reduz todas as palavras possíveis ao seu radical, removendo prefixos e sufixos derivados de um mesmo radical, ajudando a diminuir a dimensionalidade do processamento do texto porque palavras diferentes derivadas de um mesmo radical, ambas passam a ser representada pelo radical, como, por exemplo: “testando” e “testado” passam a ser o radical “test” ambas as palavras têm o mesmo valor semântico.
Nesse processo podem ocorrer alguns erros como “Overstemming” e “Understemming”.
Overstemming acontece quando o processo retira caracteres que não fazem parte de uma flexão ou derivação da palavra, mas fazem parte do radical. Pode resultar em um mesmo radical para palavras distintas.
Understemming ocorre quando ainda sobram caracteres de derivação ou flexão da palavra após o processo de stemming. Podendo resultar em radicais distintos para palavras de mesma origem.
O algoritmo e treinamento

Antes de fazer o treinamento precisamos do algoritmo para treinar. Um dos algoritmos mais utilizados em problemas de classificação é o ‘Naive Bayes’, baseado no teorema de Bayes, utiliza um método estatístico simples para reconhecer padrões. O algoritmo Naive Bayes assume que existe uma independência entre os dados que será dado como entrada para treinamento, no nosso caso, cada palavra será independente uma da outra e a presença ou não de uma no comentário não está relacionada com qualquer outra palavra.
“Em um processo de classificação no qual um exemplar com classe desconhecida seja apresentado, o Naive Bayes tomará a decisão sobre qual é a classe daquele exemplar, por meio do cálculo de probabilidades condicionais. Ele faz isso calculando as probabilidades de ele pertencer à cada uma das diferentes classes existentes no conjunto de treinamento e então classifica o exemplar pela classe com maior probabilidade.” Fonte
Após o pré-processamento temos os dados limpos, consistentes, podemos enviá-los como entrada para o treinamento do algoritmo escolhido. O algoritmo tentará localizar padrões e características que mapeiam o comentário para sua classe já definida.
O naive bayes entende cada texto como algo chamando bag-of-words, que
representa a frequência que cada palavra aparece no texto. Tomando como
exemplo os comentários: "que filme ruim" e "filme muito ruim, não gostei"
como negativo e "muito bom, gostei muito desse filme" como positivo,
gerando a bag-of-words de todos os comentários temos o seguinte:
["que", "ruim", "filme", "muito", "não", "gostei", "desse", "bom"]
Assim, podemos representar os comentários de exemplo como uma frequência de palavras:
| Comentário/Palavra | que | ruim | filme | muito | não | gostei | desse | bom | Classe |
|---|---|---|---|---|---|---|---|---|---|
| que filme ruim | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | Negativo |
| filme muito ruim, não gostei | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | Negativo |
| muito bom, gostei muito desse filme | 0 | 0 | 1 | 2 | 0 | 1 | 1 | 1 | Positivo |
Dessa forma, o algoritmo calcula a probabilidade de cada palavra pertencer a cada classe, nesse exemplo simples, podemos perceber que a palavra “ruim” tem uma maior probabilidade de ser da classe Negativo.
Teste e avaliação

Uma parte dos dados de treinamento é separado, e não utilizados na etapa anterior, para servir como dados de teste, após o treinamento, esses dados são enviados para o algoritmo para que seja feito a classificação dos mesmos pelo algoritmo treinado, esses dados de teste não devem ser nenhum dos mesmos utilizados na etapa de treinamento. Após o teste normalmente temos algumas informações de desempenho do algoritmo como, por exemplo, a acurácia, quantidade de falsos positivos e falsos negativos, entre outras.
Com essas informações podemos e devemos analisar a qualidade do treinamento e do algoritmo e perceber se atende o objetivo final, como Machine Learning é um processo empírico, caso não atenda a necessidade, podemos realizar a escolha de um outro algoritmo e proceder com as etapas de treinamento, teste e avaliação novamente até que se encontre alguma técnica que resulte em métricas aceitáveis para o problema.
Let’s code
Primeiramente vamos criar um projeto novo usando o Leiningen.
Caso não saiba como criar um projeto em clojure, tem um artigo com uma
introdução para criação projetos e dependências em Clojure:
No terminal vamos executar o seguinte comando:
lein run
Iremos utilizar duas bibliotecas para auxiliar o desenvolvimento, a
snowball-stemmer e a clj-ml. A snowball tem uma função de stemming e
suporte ao idioma português, e a clj-ml é uma lib de machine learning,
tem algumas funções e algoritmos prontos para nós usarmos. Então vamos
adicioná-las como dependências no arquivo project.clj.
Após, dentro do diretório raiz do projeto, vamos executar o comando para
instalar as depêndencias.
lein deps
Para separar as funções, iremos criar um novo arquivo chamado
pre-processing dentro do diretório src/comment_analysis, nesse arquivo
irá ficar as funções de pré-processamento dos comentários.
No início do arquivo vamos definir o namespace e fazemos os requires dos
namespaces que iremos usar (linha 1).
Definimos uma função stems usando a lib snowball (linha 6).
Logo após temos a função get-stemmin-words, que recebe um comentário,
cria um vetor das palavras e faz o processo de stemming em cada palavra
do comentário (linha 8).
A função remove-stop-words é responsável por fazer a remoção das
stop-words do comentário que recebe por parâmetro (linha 22).
A deaccent remove as acentuações das palavras, deixando as letras sem
acentos (linha 26).
A função remove-punctuation-and-symbols faz o processo de remoção de
pontuações e alguns simbolos e caracteres (linha 33).
Após temos a função remove-unnecessary-spaces que remove os espaços
extras que tiverem no comentário, deixando apenas um espaço onde deva
ter (linha 37).
Temos a função remove-excess-characters que remove os caracteres
excessívos, por exemplo a palavra “muuuuuito” vira “muito” (linha 41).
A função make-bag-of-words criará a nossa lista de todas as palavras
existentes no datasset, essa lista será utilizada para na criação do
algoritmo de classificação e preparação dos dataset de treinamento e
teste (linha 45).
Após temos a função prepare-dataset que irá preparar o nosso dataset
antes de ser usado para o treinamento e teste do nosso algoritmo (linha 53).
E a função “principal” preprocess que na prática executa as outras
funções em sequência passando o comentário que recebe por parâmentro.
No arquivo core.clj iremos escrever nosso código para preparar os
comentários, montar nosso datasset para ser usado para treinamento e
teste do algoritmo. Primeiramente vamos fazer o require dos namespaces.
Após vamos criar duas funções para fazer a leitura dos arquivos que
contém os comentários, esses arquivos estarão em um diretório comments
na raiz do projeto.
A função get-comment-and-class recebe uma string do comentário e sua
classe e retorna um map separando o comentário da classe, já passado pelo
pré-processamento, no formato.
{:comment comentario :class class}
A próxima função get-frequencies-words recebe uma estrutura gerada pela
função get-comment-and-class e retorna um map com cada palavra, já
passado pelo processo de stemming, como chave e a quantidade dessa
palavra no comentário como valor, além da classe do comentário.
Por exemplo, o comentário: clj {:class 0 :comment "eu nao gostei desse filme"}
ao ser passado para a função get-frequencies-words retorna a seguinte
estrutura.
{
:class 0
:eu 1
:nao 1
:gost 1
:desse 1
:film 1
}
As duas funções seguintes são usadas para construir um vetor de map com
a quantidade das palavras de todos os comentários, esse processo executa
separado para os comentários positivos e para os negativos.
Usando o mesmo comentário anterior como exemplo, essa função retorna o
seguinte vetor.
[{:class 0 :eu 1 :nao 1 :gost 1 :desse 1 :film 1} ...]
Como citado acima, uma parte dos dados de dataset é separado para treino
e outra para teste, a função divide-dataset faz esse processo. A função
recebe o vetor retornado pelas funções define-data-words-* e divide em
~70% dos itens para treino e os outros ~30% para teste.
Essa função retorna também um map no seguinte formato:
{
:train [{:class 0 :eu 1 :nao 1 :gostei 1 :desse 1 :filme 1} ...}]
:test [{...} {...}]
}
A função define-data-words cria o conjunto de dados para treino e teste
chamando as funções anteriores e fazendo a união dos dados referente aos
comentários negativos e positivos para treino e teste, para ser mais
aleatório embaralho os dados usando a função shuffle.
Retornando uma estrutura semelhante a anterior, mas com todos os dados
dos comentários positivos e negativos no mesmo vetor.
{
:train [{:class 0 :eu 1 :nao 1 :gostei 1 :desse 1 :filme 1} ...}]
:test [{...} {...}]
}
Temos as funções para criar os datasets de treino e teste utilizando as
funções da lib clj-ml, criando o dataset, aplicando filtro no atributo
referente a classe do comentário e definindo esse atributo como classe.
E a função que realiza o treinamento do classificador e a avaliação do
mesmo, logo após imprime as informações de desempenho do algoritmo.
A função main quando chamada realiza as chamadas para as outras funções
para criação dos datasets e após chama a função de treinamento e avaliação
do classificador, assim mostrando as informações de desempenho do algoritmo.
Entrando no diretório raiz do projeto e executando o comando lein run
para iniciar a execução do código. Inicia o processo de preparação,
treinamento e teste do algoritmo utilizado, assim que acabar irá mostrar
os resultados da avaliação.
As informações retornadas serão semelhantes a estas:
Destaque para o sumário (linha 33), que nos mostra a quantidade e
porcentagem de comentários classificados corretamente e incorretamente,
o total de comentários utilizado para o teste. Também temos a matrix de
confusão (linha 55) que mostra quantos comentários foram classificados
como positivos (1) e negativos (0).
No exemplo podemos identificar que de 396 comentários negativos ele classificou 300 como negativos (correto) e 96 como positivos (incorreto) e de 396 comentários positivos ele classificou 210 como positivo (correto) e 186 como negativo (incorreto). Podemos perceber que está acertando mais os comentários negativos do que os positivos. Assim podemos avaliar as métricas necessárias e definir se atende as necessidades do problema em que será aplicado.
Conclusão e observações
No caso de estudo foi usado Machine Learning para classificação de
comentários sobre filmes, esses comentários foram retirados de um site
sobre cinema usando webscraping e salvos em arquivos de textos, para
definir de qual classe os comentários eram, Positivo (1) e Negativo (0)
foi utilizado a nota dada, também no respectivo site, foi assumido notas
4 e 5 como um comentário Positivo e notas igual ou abaixo de 2 como um
comentário Negativo.
Foi usado um total 2634 comentários, metade negativos e metade
positivos, foi usado o algoritmo Naive Bayes como classificador e
utilizado ~70% dos comentários de cada classe para treinamento e os
outros ~30% para teste. Após o treinamento e teste devemos observar as
métricas e avaliar se são aceitáveis e atendem o problema em que será
aplicado.
-
Durante o processo de captura dos dados foi notado que, mesmo alguns comentários visivelmente positivos estavam com nota baixa e consequentemente entraram como comentários negativos, o oposto também foi observado. Casos assim podem causar inconsistência no treinamento do algoritmo ocorrendo uma baixa qualidade nos resultados de teste, a qualidade do dataset tem enorme influência nos resultados finais.
-
O processo de remoção de stopwords e stemming também pode influenciar no treinamento, a lista de palavras consideradas como stopwords tem de ser avaliada e observado se não está removendo palavras que tenham importância para o contexto, realizei alguns testes com e sem o processo de stemming e remoção de stopwords e o melhor resultado ocorreu deixando os dois processos.
O código completo podem ver aqui
Dúvidas, sugestões, críticas… podem deixar nos comentários, e compartilhar caso gostou :D.
Referências:
- http://bdm.unb.br/bitstream/10483/11042/1/2015_LucasBragaRibeiro.pdf
- https://www.maxwell.vrac.puc-rio.br/13212/13212_4.PDF
- https://www.infoq.com/br/presentations/classificacao-de-documentos-baseada-em-inteligencia-artificial
- https://www.safaribooksonline.com/library/view/clojure-for-data/9781784397180/ch04s13.html
- https://pt.slideshare.net/jonmagal/naive-bayes-16122964
- https://pt.slideshare.net/plataformatec/classificao-de-textos-dev-in-sampa-28nov2009
- https://pt.slideshare.net/matheusgaldino355/teoria-decisao-bayes
- https://gabrielschade.github.io/2018/04/16/machine-learning-classificador.html